A recent piece by Barron’s titled “Here Come the Teens: They Can’t Vote, but They’re Old Enough to Buy Stocks” speaks favorably about today’s young get-rich-quick “investors” who scan Reddit forums for ideas and risk it all on YOLO trades. Firms like Robinhood and public figures like the King of SPACs encourage this behavior by pretending these morons stand a chance against the most sophisticated institutional algorithms in the world. “At 16, Davé isn’t your typical trader,” says the piece. Dave sure isn’t.
BSD prop traders are all but gone now. In their place are stock trading algorithms that consume data voraciously and use it to generate alpha. And they’ve been at it for a long time. Today’s teen traders may not know the name Jim Simmons, but this mathematician’s algorithms are often on the other side of the trade.

From a 2019 Wall Street Journal article titled “The Making of the World’s Greatest Investor”:
Today, Mr. Simons is considered the most successful money maker in the history of modern finance. Since 1988, his flagship Medallion fund has generated average annual returns of 66% before charging hefty investor fees—39% after fees—racking up trading gains of more than $100 billion. No one in the investment world comes close. Warren Buffett, George Soros, Peter Lynch, Steve Cohen, and Ray Dalio all fall short.
Credit: WSJ
Big data is what drives these returns, something we wrote about before in our piece on Eight Ways to Use Alternative Data for Trading. The same data can also be used by businesses to gain insights into how operations can generate more revenues and profits. The most interesting data sets are those emerging as a result of software eating the world. Some refer to it as “data exhaust,” others call it “ambient intelligence“, but both terms describe big data that’s being produced constantly based on people’s normal everyday activities. From this data, a wealth of insights can be mined.
6 Companies Monetizing Alternative Data
AlternativeData.org is run by a bunch of former financial analysts, data analysts, and engineers who help institutional investors make the best of all the alternative data sets out there. We perused their database to find some interesting alternative data sets that can be used to take money from teenagers or improve how your business operates.
Data Exhaust from Online Advertising
When you’re generating data about people’s online habits, you probably don’t want to make a big fuss about it. We could hardly find any information about a Florida company called Cyberstream.io except that they know a lot about what people are doing online. Since 2010, they’ve been working with the world’s largest ad exchanges to monitor for digital ad fraud. (Anyone who has ever tried to click their own website ads knows what we’re talking about here.) Cyberstream collects real-time data from over one billion unique visitors monthly via JavaScript code embedded in over 300 million URLs and apps. That translates into an ability to monitor 30% of the world’s online population.
Data Exhaust from Online Purchasing
Similar to Cyberstream, Hong Kong startup Measurable AI doesn’t talk a lot about who they are, but they’re doing something equally extraordinary. Measurable AI collects billions of e-receipts collected directly from users who choose to share their data via a number of consumer apps. (All those “free” apps you use aren’t exactly free.) The company specializes in emerging markets – ten of them – and the sort of data they’re gathering includes spending habits from large companies commonly found in emerging markets.

The company’s blog contains some interesting information on how their data sets are used, like how to mine for “whales” in the gaming community, the small group of people who contribute a large percentage of revenues in successful games. Studies have shown that just 1% of users are responsible for over 59% of the revenues on iPhone’s marketplace in the United States. Measurable AI can help you find these people.
Data Exhaust from Computer Networks

Third in our list of companies with a one-page web presence is Pasadena California’s own Del Mar Networks which doesn’t even provide a physical address. All we know is some guy named Aiden works there and he’s involved in producing a data set that tracks web traffic at a hardware level. Anyone who has ever used tools like Google Analytics to measure their web traffic knows how data accuracy can be shifty at best. We use these tools and often see mystery spikes or unexplainable phenomenon. (Good luck asking Google to explain the data. They’re too busy crafting their ever-changing “User Experience” hoops publishers need to jump through.) Del Mar Networks has developed “novel techniques for measuring web traffic at minute-level resolution using direct observations of web infrastructure.” That’s about as close to ground truth as you’re going to get.
Data Exhaust from the Courtroom
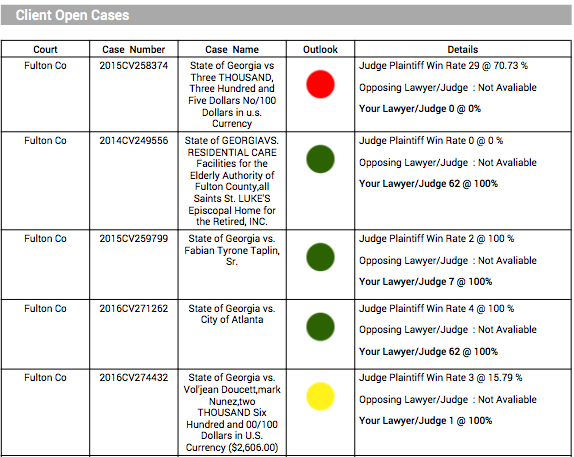
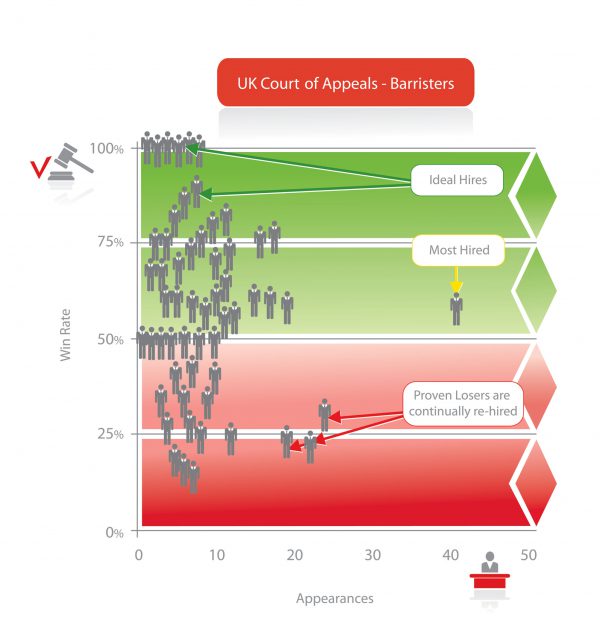
Most publicly available data sets have already been mined to exhaustion, but they can always be resurrected by doing some good old-fashioned data warehousing. A company called Premonition has put together the world’s largest litigation database which has artificial intelligence algorithms scouring the world, adding millions of legal cases every day. (They claim their algos can read 50,000 pages in under a second.) Consequently, they’re able to start assigning success rates for attorneys which are ready to be uploaded into Salesforce.

One example of how this data comes in handy would be the AbCellera lawsuit against Berkeley Lights. As shareholders in the latter, we were happy to hear the lawyer defending Berkeley Lights, Morgan Chu, has been described as “beyond doubt the most gifted trial lawyer in the USA” who “delivers staggering results for clients.” Wouldn’t it be great to replace these superfluous statements taken from Mr. Chu’s website with his actual court room record, then do the same for the plaintiff? You could then start assigning probabilities to court outcomes. Or better yet, let an artificial intelligence algorithm do it for you.
Data Exhaust from Investors
We monitor hundreds of stocks to keep our fingers on the pulse of today’s hottest trends. To do that, we created portfolios over at Investing.com which can then be tied to price alerts. It’s a free service that also allows you to upload your actual holdings and track performance, a useful tool for any investor who has multiple brokerage accounts they’d like to aggregate. As the third biggest global financial website out there with over 20 million users a month, they’re generating a lot of data exhaust, and a few years back they started monetizing it. Available data includes things like sentiments, price alerts, portfolios, and what their users are searching for. It’s not just startups monetizing data exhaust.
Data Exhaust for Investors
Our own tech investment methodology involves scouring financial filing documents to find red flags because what a company says to the SEC and what they tell the world can be two dramatically different things. For example, the way a company breaks from their routine corporate babble telegraphs what’s happening inside. A simple inconsistency can say a lot. For example, we noticed these two conflicting sentences in a company’s 10-K recently:

Knowing about an executive’s departure before it’s announced (we’re not saying that’s what happened in the above example) can be very valuable information to have. A paper called Lazy Prices talks about how “changes in language referring to the executive (CEO and CFO) team, regarding litigation, or in the risk factor section of the documents are especially informative for future returns.” These are the sorts of insights a company like Fraud Factors might be able to tease out. For example, they provide 56 fields that measure linguistic features within 10-K filings.

We often compare information at yearly intervals to see how forecasts change, or even didn’t change. If every year a company says revenues are five years away, something is wrong. Looking for inconsistencies is just one insight of many Fraud Factors provides by scouring all financial filings submitted to the SEC for red flags, something we’d argue the SEC ought to be doing already.
Some Additional Comments
Think about how much data exhaust a company like Walmart spews forth every day. You can bet Walmart is monetizing that data, but not by selling it. Large companies create internal value with their data. When a company can’t create value using their own data, the next best thing to do is sell it – Investing.com being a good example. Then you have companies that don’t generate the data themselves, but have figured out how to collect data from others, structure it, aggregate it, and sell it.
The question we kept asking ourselves when researching this piece is how these companies are accomplishing what they say they are without availing themselves of some sinister methods? (Insert your own conspiracy theory here.) Alternative data providers don’t talk a lot about how they run their operations, and that’s because they probably want to avoid the prying eyes of data privacy advocates.
Technology will advance whether people complain about it or not. If controversial AI algorithms generate incredible amounts of value for a firm, they’ll bury them so deeply in their Frankenstack that they’ll never be found. And all these political activists masquerading as “ethical AI experts” calling for “transparency in AI” will never know the difference. Point is, we’re all monitored very closely in today’s day and age, whether we like it or not.
Lastly, we can provide no assurance that any of the companies named in this piece are providing accurate and legitimate data. Half of them run one-page sites with little information other than an address. We can only assume the folks at AlternativeData.org vetted them thoroughly before selling their data. Synthetic data is easy to create these days, so always make sure to do your own due diligence before buying data from anyone.
Conclusion
There are a few lessons to be learned here. The first is that today’s teenagers are best served saving their money and putting it towards a STEM education so they can add value to society instead of becoming “creators” searching for handouts. The second is that if you’re not using big data to drive your business, you’ll be quickly passed up by those who are.




{kind=link}