Getting to the Shortlist
The purpose of Premonition is to provide the market with transparency about the lawyers that win, and the lawyers that lose. With the worlds largest litigation database, we’re helping customers around the globe to assess lawyer performance as part of their lawyer selection process.
It is not an absolute, it’s indicative. Other factors such as lawyer availability, price, personal chemistry, etc., may affect final selection but, for the first time, you can now add performance metrics to that mix.
Determining Wins
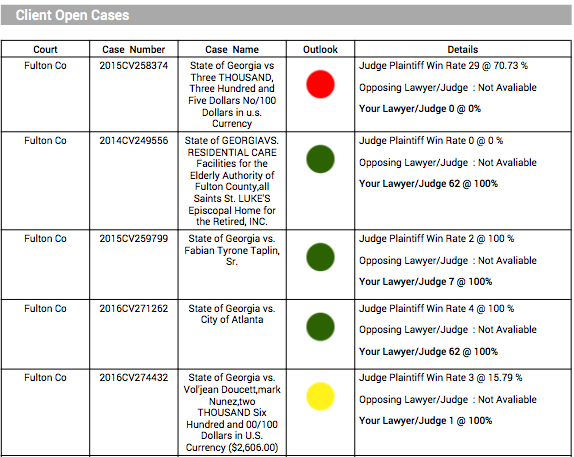
At the heart of the Premonition Method is the determination of an attorney’s “win rate.” Of course, what constitutes a win is often hotly debated. If you call both lawyers on a closed case, both will claim to have “won”. We consulted with a number of Lawyers and Judges asking them about the general winners and losers for various dispositions (we have over 100 types in the system). There was broad agreement that the fairest approach would be to consider judgements as a “win” for plaintiffs, dismissals as a “win” for defendants and settlements should be categorized consistent with local court rules, which generally categorize a settlement as a “dismissal.”
While the system is not perfect, it does create a “level playing field” for which reasoned judgments can be made of a group of attorneys operating in the same judicial environment. Thus, comparisons between local attorneys operating on the same types of cases in the same jurisdiction can be more “data based” and less subjective. This is the ultimate goal of Premonition. Premonition is not a “rocket science” system where we strive for 100% unarguable analysis of every case; rather its function is to spot trends and outliers. It does this very well as data is “smoothed out” over 1,000s of cases.
Case Difficulty
Every case differs in difficulty. Premonition does not asses the difficulty of a case. Attorneys often claim to “only take the toughest cases” when explaining low Win Rates. Occasionally this is true. However, our data indicates that as an overall excuse this is a false foundation as it too is “smoothed out” over a large number of cases.
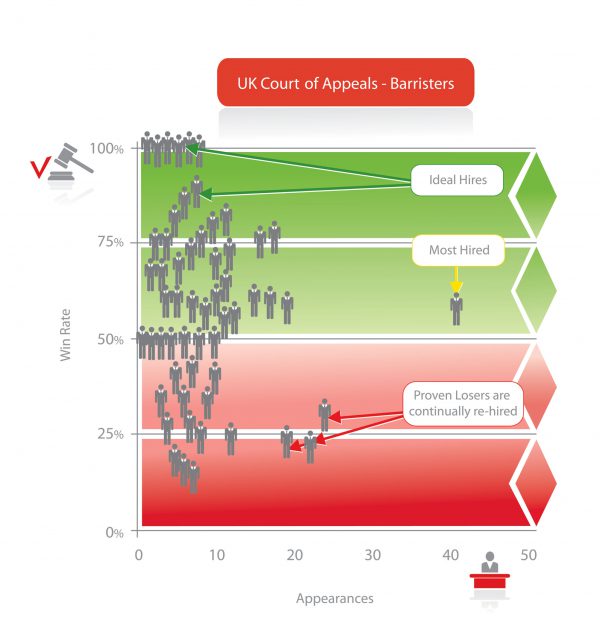
It is also worth noting that in some jurisdictions such “cherry picking” is prohibited. For example, the United Kingdom has a “cab rank rule” preventing Barristers from cherry picking easy cases and the Premonition results are similar to the United States. This also supports the conclusion that even in the United States, cherry picking is not much of a factor.
Finally, while Premonition is not designed to identify the “surgeon” attorneys that only work the hardest cases, it does group cases with those of similar difficulty by using case type, sub type and parties. For example, Tax Court is notorious for its low Win Rates against the IRS, however top performing attorneys still stand out, not by their wins, but because they lose less. Cases group by court type (Appeals Court being a more rigorous black letter law venue than small claims), and by Judge where certain cases, e.g. complex business claims are assigned to certain Judges. Over time
case difficulty variations are also smoothed out over large numbers of cases and Attorneys who only take easy cases will de-select themselves when approached.
Multiple Attorney and Firm Only Cases
Premonition looks at the first listed attorney for each side and ignores the others. This not only makes using the system easier to use but it also recognizes the practical reality that the lead attorney usually has the greatest impact on the result. In courts where the individual attorney names per party are not identified specifically, Premonition uses an algorithm to predict which individual attorney likely represents which party, then selects the 1st one for each side to analyze. However, co-counsel can be analyzed if specifically requested by the client.
Gender and Diversity
Premonition matches names to census data and calculates the likely gender and race based on first and last names. We find that at scale Premonition’s accuracy approaches that of the census itself.
Overall data accuracy
Premonition data cannot be more reliable than the public record.